Nous allons démarrer notre série d’articles sur vSphere Replication en présentant les principaux concepts du produit : comment ça marche ? Quels sont les composants ? Les flux ? Puis nous verrons quelques architectures possibles.
Concepts
Mais tout d’abord : qu’est-ce que c’est ? Comme son nom le laisse supposer, vSphere Replication est outil permettant la réplication de machines virtuelles d’un emplacement à un autre. Cet emplacement (source ou destination) peut être un serveur ESXi, un cluster ou un datacenter. On peut donc se protéger d’une panne isolée d’une machine virtuelle, mais aussi d’une panne complète de site.
Composants
vSphere Replication se compose (au minimum) d’un serveur de gestion et d’un serveur vSphere Réplication. C’est la première source de confusion ! On prendra donc soin de ne pas confondre :
- le serveur de gestion vSphere Replication qui configure les réplications, gère les permissions et maintient le lien avec le serveur vCenter…
- … avec le serveur vSphere Replication, qui s’occupe de déplacer les bits. Il les récupère en provenance des machines virtuelles source et se charge de les écrire sur les disques de destination.
Et vous voulez rire ? La première appliance que l’on déploie contient le serveur de gestion vSphere Replication et un premier serveur vSphere Replication, le tout dans la même VM. Voilà de quoi accroître la confusion, sauf pour nous maintenant, qui le savons 🙂 ! Notons au passage que dans des versions précédentes ces deux composants étaient livrés séparément, ceci expliquant cela.
Profitons-en également pour mettre en avant le nombre de composants vSphere Replication possibles dans l’environnement :
- Il y a une relation de 1 pour 1 entre le serveur vCenter et le serveur de gestion vSphere Replication.
- Il y a une relation de 1 pour n entre le serveur de gestion vSphere Replication et les serveurs vSphere Replication (1 pour 10, en fait).
Autrement dit, pour 1 vCenter, on aura toujours 1 serveur de gestion et potentiellement plusieurs serveurs vSphere Replication… (sachant que le premier est intégré au serveur de gestion – rappel).
Il y a aussi un agent “client”, qui est déjà présent sur ESXi, et qui va piloter la réplication à proprement parler au niveau de la machine virtuelle source. Il a pour charge d’envoyer les données au serveur vSphere Replication.
On notera enfin la présence d’un plugin web qui permet la gestion depuis le web client, ainsi que d’une base de données qu’on pourra externaliser, mais cela semble peu utile.
Fonctionnement bas niveau
En local
Comment ça marche ? La machine virtuelle A du serveur ESXi1 est répliquée vers le serveur ESXi2 du même site par un administrateur. Dès lors, la copie initiale se met en place. Les fichiers vmdk de la VM A sont lus et éventuellement comparés avec un pré-copie présente à destination (si elle existe). Puis une liste de blocs à transférer est établie et la copie commence.
Une fois la copie initiale terminée, on passe en mode synchronisation. Un filtre SCSI enregistre tous les blocs modifiés sur les fichiers vmdk source et en conserve une copie dans des fichiers .psf stockés avec la machine virtuelle. Ces fichiers contiennent des pointeurs vers les blocs modifiés, pas les blocs eux-mêmes ! Aux intervalles définis, cette liste de blocs est utilisée pour générer un paquet de mises à jour qui vont être envoyées au serveur vSphere Replication, qui va attendre d’avoir tout reçu pour écrire les données sur les disques de destination.
Le fonctionnement est très similaire à du CBT (Changed Block Tracking), mais ce n’est pas du CBT : il n’y aura pas d’interférence avec le backup.
A distance
Dans notre exemple, nos serveurs ESXi source et destination étaient sur le même site. Mettons maintenant notre serveur ESXi1 est sur le site 1, et qu’ESXi2 sur le site distant 2. Quelle est la contrainte ? Comme nous l’avons vu, c’est le serveur vSphere Replication qui effectue les écritures disque sur le site de destination. Il doit donc être placé sur le site de destination, afin d’avoir accès aux disques. Ce n’est pas un problème, car l’intelligence (enfin, une partie de l’intelligence) est au niveau de l’agent ESXi qui gère les mises à jour de bloc de la machine source, et que seuls les blocs modifiés passeront sur le réseau vers le serveur vSphere Replication.
La conséquence de ce mode de fonctionnement est que nous devons avoir un serveur vSphere Replication sur chaque site destiné à recevoir des réplications de machine virtuelle. Ce qui n’est pas un problème, mais un élément à prendre en compte.
Sur le réseau
Malheureusement vSphere Replication n’intègre aucun mécanisme de régulation de bande passante, ni ne permet de limiter le traffic de réplication à certaines heures. Cela peut poser problème sur des liens à faible capacité. Si vos outils le permettent, vous pouvez identifier et classifier le traffic réseau causé par vSphere Replication grâce aux ports utilisés :
- 31031 : réplication initiale
- 44046 : réplications suivantes
A défaut de QoS, si vous avez vraiment besoin de limiter le traffic vSphere Replication, une manière de limiter le trafic causé par vSphere Replication serait de configurer un groupe de port dédié pour le serveur vSphere Replication et de configurer du traffic shaping entrant, mais cela requiert des dvSwitchs et donc la version Enterprise Plus de vSphere.
Architectures possibles
La contrainte
D’après ce que nous avons vu jusqu’à présent, tout est simple. Oui… Mais non ! Car il y un loup : pour restaurer une VM répliquée, il vous faut un accès au serveur de gestion vSphere Replication et au serveur vCenter !
Autrement dit, il vous faut votre vCenter et le serveur de gestion vSphere Replication sur le site de secours, ce qui n’est généralement pas le cas.
Quelle solution ? Eh bien, il n’y a pas vraiment le choix : si vous envisagez d’utiliser vSphere Replication comme outil de protection de site, il vous faut un second serveur vCenter et un second serveur de gestion vSphere Replication sur le site de secours.
Cette nouvelle contrainte étant intégrée, faisons le tour de quelques architectures possibles.
Protection de machines virtuelles sur un site
Cas d’usage : nous souhaitons protéger une ou plusieurs applications, voire un cluster de production complet, et reprendre l’activité de ces applications dans le même site, sur un matériel de secours dédié.
Contraintes : il faut du matériel dédié pour la reprise d’activité et du matériel dédié pour la plateforme de management (qui doit inclure le serveur vCenter, le serveur de gestion vSphere Replication, et probablement aussi des éléments d’infrastructure (contrôleur de domaine)).
Proposition d’architecture : nous allons combiner le matériel de reprise d’activité avec le matériel de management pour en faire une plateforme dédiée à ces fonctions. Le cluster de production se consacre uniquement à l’exécution de serveurs de production. Les deux environnements pourraient être dans des salles séparées à condition de garantir un réseau fiable entre les deux salles.
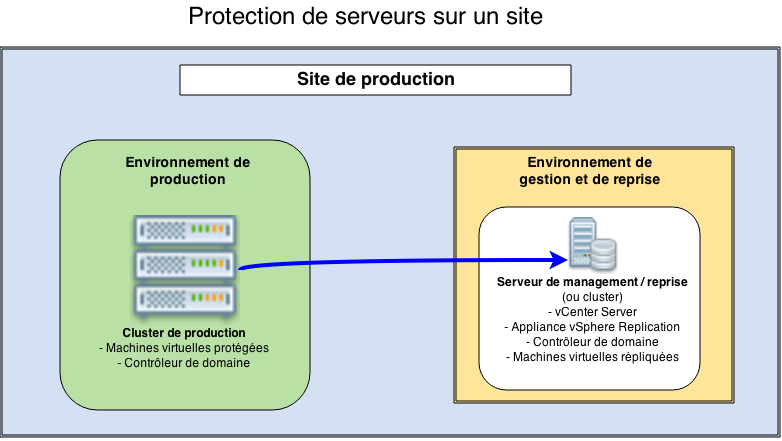 Remarques : un avantage de cette solution est qu’il n’y a pas vraiment de matériel dormant, puisque l’environnement de reprise est utilisé pour gérer la production (mais il doit tout de même être dimensionné pour pouvoir redémarrer les applications protégées !).
Remarques : un avantage de cette solution est qu’il n’y a pas vraiment de matériel dormant, puisque l’environnement de reprise est utilisé pour gérer la production (mais il doit tout de même être dimensionné pour pouvoir redémarrer les applications protégées !).
Protection de site(s) avec site de secours dédié
Cas d’usage : une société loue un espace / des serveurs chez un hébergeur pour y installer un environnement de reprise d’activité. Elle va y répliquer des serveurs applicatifs provenant d’un ou plusieurs sites de production.
Contraintes : il faut une bonne connexion réseau entre le(s) site(s) de production et l’environnement de reprise. Le matériel du site de reprise doit être dimensionné correctement pour assurer la reprise du plus gros site.
Proposition d’architecture :
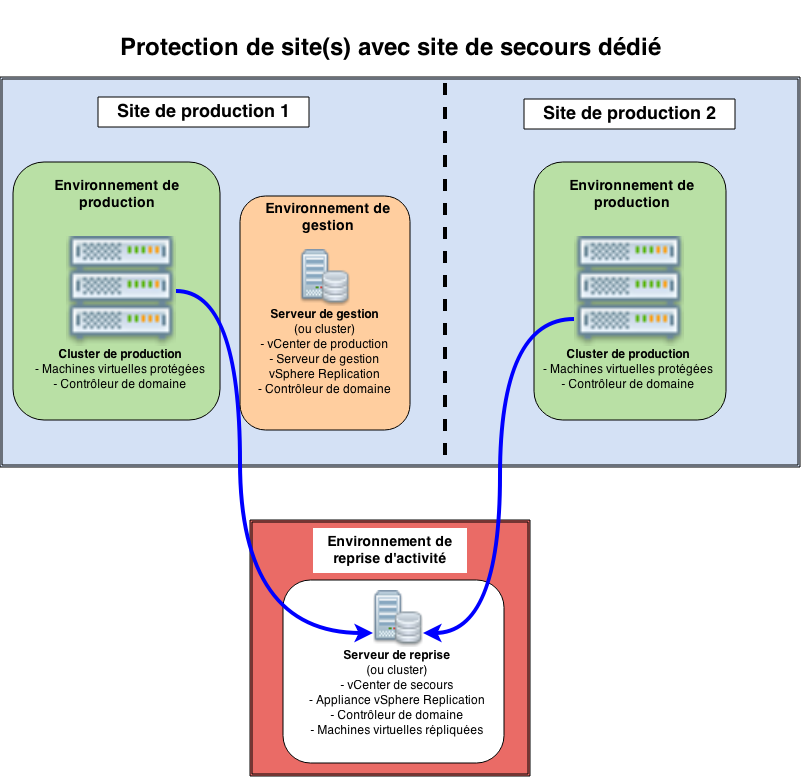 Remarques : on peut bien sûr se limiter à la protection d’un seul site de production. On remarquera ici que l’environnement de gestion (en orange) est à part pour des raisons de lisibilité, mais pourrait tout à fait être intégré au cluster de production. On remarque également que dans ce scénario, un seul environnement de gestion gère les différents sites de production.
Remarques : on peut bien sûr se limiter à la protection d’un seul site de production. On remarquera ici que l’environnement de gestion (en orange) est à part pour des raisons de lisibilité, mais pourrait tout à fait être intégré au cluster de production. On remarque également que dans ce scénario, un seul environnement de gestion gère les différents sites de production.
Protection de sites croisés
Cas d’usage : une société dispose de deux sites de production et chaque site va protéger l’autre site. Par rapport au scénario précédent qui était sur le mode actif / passif, ici on est plutôt en actif / actif. On pourra bien sûr démultiplier cette architecture en fonction du nombre de sites.
Contraintes : chaque site va disposer de son propre environnement de gestion (serveur vCenter, serveur de gestion vSphere Replication…). Pour conserver une administration centralisée, on pourra opter pour une installation de vCenter en Linked Mode ; à défaut les deux sites seront gérés séparément. Les environnements de production doivent être dimensionnés pour accueillir les machines répliquées en cas de reprise.
Proposition d’architecture :
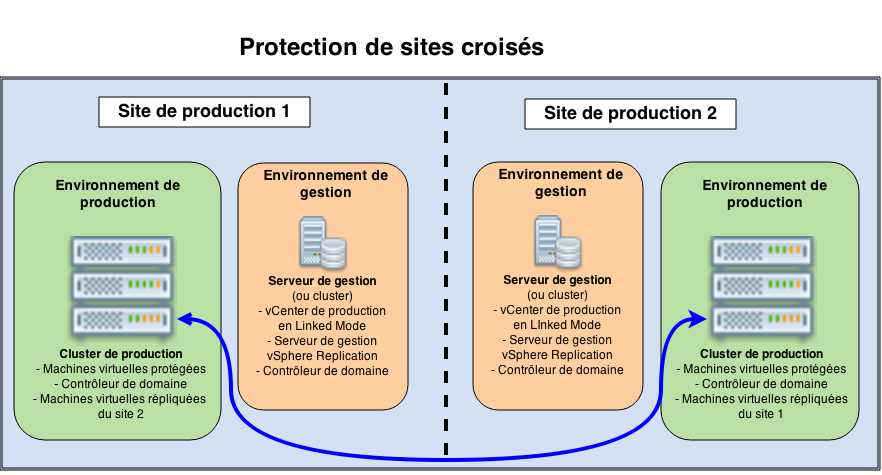 Remarques : ici aussi, les environnements de gestion sont séparés des environnements de production pour rendre le graphique plus lisible (et car cela a du sens lorsque l’environnement atteint une certaine taille), mais dans cette topologie, ces deux environnements pourraient tout à fait être intégrés dans le même cluster.
Remarques : ici aussi, les environnements de gestion sont séparés des environnements de production pour rendre le graphique plus lisible (et car cela a du sens lorsque l’environnement atteint une certaine taille), mais dans cette topologie, ces deux environnements pourraient tout à fait être intégrés dans le même cluster.
Conclusion
Nous avons vu comment fonctionne le système de réplication et proposé trois topologies type, parmi une multitude de possibilités. Le système est en effet flexible et saura s’adapter à vos besoins!
Dans la suite de cette série d’articles, nous allons mettre en pratique le produit dans un déploiement de type secours dédié, où nous avons un serveur dédié dans un site distant qui sera utilisé comme destination de réplication et serveur de PRA si la situation l’exige.